오늘 다룰 내용은 Reactor Netty HTTP Client에서 간헐적으로 발생했던 Connection prematurely closed BEFORE response 에러와 관련된 내용 입니다. 왜 이 에러가 발생하는지 원인을 추적하는 과정과 어떻게 대응 했는지에 대한 내용을 살펴 보려고 합니다.
문제의 발단
서비스 오픈 후 트래픽이 증가하면서 기존에는 발생하지 않던 새로운 종류의 에러가 발생하기 시작 했습니다. 바로 Connection prematurely closed BEFORE response 에러 였습니다.

에러 메세지만 봐도 응답을 받기 전에 커넥션이 끊어졌다는 메세지 였고, 이는 네트워크 문제가 발생했음을 알 수 있는 메세지 였습니다. 과연 원인이 무엇일까, 원인을 찾아내기 위해 tcpdump를 이용해서 패킷을 수집하기 시작 했습니다.
패킷 덤프 분석
서비스가 동작하는 환경은 쿠버네티스 기반의 환경 이었고, 다수의 파드들이 있었기 때문에 모든 파드에서 패킷 덤프를 수집할 순 없었습니다. 그래서 우선 파드 별로 에러의 발생 빈도를 확인 했습니다. 혹시 특정 파드에서만 발생하는 문제는 아닐까 하는 의심도 있었기 때문 입니다. 하지만 확인해 보니 모든 파드에서 고르게 에러가 발생하고 있었습니다. 그래서 마음에 드는 파드를 랜덤하게 아무거나 하나 골라서 해당 파드에서 발생하는 패킷을 수집하기로 했습니다. 파드에서 직접 tcpdump를 이용해서 패킷 덤프를 생성할 수도 있지만, 컨테이너에 영향을 줄 수 있기 때문에 파드가 동작하는 노드에서 tcpdump를 이용해서 패킷 덤프를 생성하기로 했습니다. 아래와 같이 대상 파드가 동작 중인 노드에서 tcpdump 명령을 이용해서 패킷 덤프를 생성 하기 시작 했습니다.
tcpdump -i any -A -vvv -nn host <목적지 IP 주소> -w packet_dump.pcap그리고 항상 그랬던 것처럼 에러가 발생하기를 기다리기 시작 했습니다. 패킷 덤프를 생성하기 시작한지 40여분 정도 지났을까 드디어 모니터링 시스템에 에러가 잡혔습니다.
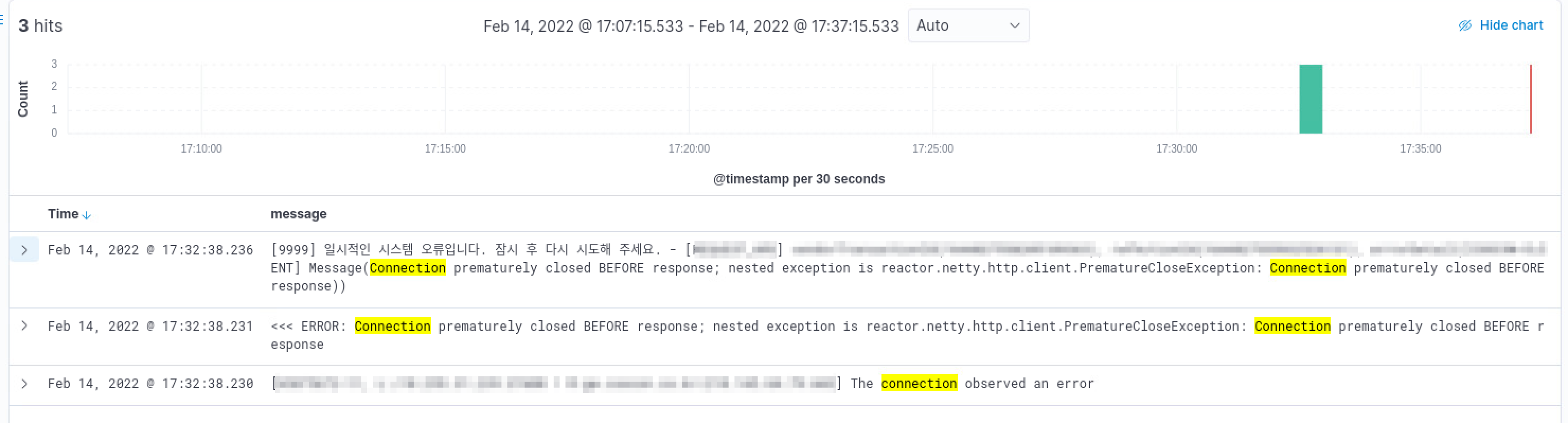
에러가 잡히자 마자 패킷 덤프를 중지 했고 와이어샤크를 이용해 수집한 패킷의 내용을 살펴봤습니다.

눈여겨 볼 부분은 81번 패킷부터 84번 패킷 입니다. 81번 패킷과 82번 패킷 사이의 시간차가 5초 인 것을 눈여겨 봐주시기 바랍니다. 클라이언트는 81번 패킷을 보내고 약 5초 정도 후에 82번 패킷을 이용해 상대방에게 요청을 보냅니다. 하지만 83번 패킷과 84번 패킷을 보면 상대방은 요청에 대한 응답을 주지 않고 FIN 패킷을 보내버립니다. 연결을 먼저 끊는거죠.
83번 패킷인 Encrypted Alert는 TLS 환경에서 연결을 끊을 때 사용하는 FIN 패킷 전에 보내는 패킷 입니다. (참고 자료 : https://support.f5.com/csp/article/K95610370)
뭔가 이상한 패킷 흐름 입니다. 요청을 보냈지만 응답은 커녕 문을 닫겠다는 패킷을 받았으니 당연히 에러가 발생하겠죠. 그렇다면 이런 현상은 왜 발생한 걸까요?
원인은 HTTP KeepAlive
이 현상의 원인은 HTTP KeepAlive 때문 입니다. 왜 그럴까요? 아래 그림을 살펴 보겠습니다.

A와 B가 서로 요청과 응답을 주고 받습니다. 여기까지가 위의 덤프 내용으로 보면 80번 패킷까지의 내용이 되겠죠. 그리고 5초 정도가 흐른 뒤 A가 GET 요청을 보냅니다. 이 패킷이 바로 82번 패킷 입니다. 하지만 B 입장에서 보면 이미 5초 동안 아무런 요청이 들어오지 않았기 때문에 이 연결은 이제 타이머가 만료 되었으니 끊어야 겠다 생각하고 FIN 패킷을 보냅니다. 그리고 이 패킷이 83번과 84번 패킷 입니다. 패킷은 RTT에 의해 상대방에 도달하는 시간이 추가로 소요되기 때문에 끊어지기 직전 그 아슬아슬한 순간에 A가 요청을 보내게 되지만 A의 요청이 B에 도착하기 전에 이미 B에서는 타이머가 만료되어 연결을 끊게 되는 겁니다. 확인해 보니 상대방 서버의 HTTP KeepAlive 타임아웃 값은 5초 였구요.
그럼 이 동작은 비정상적인 동작 일까요? 그렇지 않습니다.
이 현상은 HTTP KeepAlive 타이머 만료에 의해 발생하는 지극히 정상적인 동작 입니다.
그런데 말입니다. 이런 동작이 정상적인 동작이라면 우리만 문제를 겪고 있진 않을것 같은데 말이죠..
그렇다면 어떻게 대응할 수 있을까?
Reactor Netty의 공식 문서에 보면 이미 Connection prematurely closed BEFORE response 에러에 대한 대응 가이드가 명시되어 있습니다. (참고 자료 : https://projectreactor.io/docs/netty/snapshot/reference/index.html#faq.connection-closed) 이미 수많은 사람들이 같은 이슈를 겪고 있다는 이야기겠죠. 우리는 그 중에서도 아래 항목에 주목 했습니다.

네 맞습니다. 여기서 말하는 idle timeout이 바로 HTTP KeepAlive 타임아웃 입니다. 상대 서버가 idle timeout에 의해 연결을 끊는 경우를 의미 합니다. 그렇다면 어떻게 대응할 수 있을까요? 대응 방법에는 여러가지가 있을 수 있습니다. 상대 서버가 HTTP KeepAlive 타임아웃 값을 늘려줄 수도 있고 아예 HTTP KeepAlive를 사용하지 않도록 HTTP 헤더에 Connection: close 를 명시해서 호출할 수도 있습니다. 하지만 두 경우 모두 근본적인 대응책은 아닙니다. 먼저 HTTP KeepAlive 타임아웃 값을 늘린다고 해도 빈도 수가 줄어들 뿐 같은 에러가 계속해서 발생할 수 있는 가능성은 여전히 존재 합니다. 그리고 HTTP KeepAlive를 사용하지 않는 것은 에러는 해결할 수 있지만 성능에 영향을 미칩니다. 어떤 방법을 사용해야 할까 고민하던 중 Reactor Netty HTTP Client의 설정값 중 maxIdleTime 이라는 것을 찾아냈습니다.

maxIdleTime은 커넥션 풀에 존재하는 커넥션 중 Idle 상태로 남아있을 수 있는 최대 시간을 정의하는 값 입니다. 그리고 하단에 친절하게도 우리가 겪고 있는 이슈에 딱 부합하는 설명도 곁들어져 있습니다. 그래서 이 값을 3초로 설정하기로 했습니다. 상대방이 5초 동안 통신이 없으면 먼저 끊기 때문에 우리는 3초에 먼저 끊도록 했습니다. (물론 4초로 설정해도 됩니다. ^^) 그럼 우리는 어떤 연결이 끊어질지 미리 알 수 있고 지금처럼 요청을 보냈는데 의도치 않게 상대방에 의해 끊어져 버리는 경우는 사라지게 됩니다.
maxIdleTime을 설정한 후 배포를 하고 추이를 지켜 봤습니다. 그리고 거짓말처럼 해당 에러는 사라졌습니다.

마치며
이번에 겪은 에러는 네트워크와 관련된 메세지 였기 때문에 tcpdump를 통해 패킷을 수집하고 수집된 패킷을 분석해서 에러의 원인을 파악하는 과정을 거쳤습니다. 문제를 분석하기 위해 지난번 글에서 언급한 VPC Flow logs를 사용해도 좋았겠지만 아직 익숙하지 않아서 빠르게 해결해야 하는 문제 였기 때문에 익숙한 tcpdump를 사용 했습니다. VPC Flow logs를 통해서도 문제를 해결할 수 있었을텐데 개인적으로 문제를 해결하고 난 후에 조금 아쉽긴 했습니다.
만약 Reactor Netty HTTP Client를 사용하는 분들 중 저희와 같은 에러를 겪고 계신 분들이 있다면 maxIdleTime을 적절한 값으로 설정해서 사용해 보시기 바랍니다. 물론 에러가 발생하는 상대방의 HTTP KeepAlive 타임아웃 값을 확인하고 그 값보다 반드시 작은 값으로 설정해야 하는 것을 잊지 마시구요. 긴 글 읽어 주셔서 감사합니다.
'IT > DevOps' 카테고리의 다른 글
| VPC Flow logs는 네트워크 문제 분석에 활용할 수 있을까? (1) | 2022.02.10 |
|---|---|
| docker run 과 docker exec 재현을 통해 컨테이너 이해하기 (1) | 2022.01.25 |
| aws-node-termination-handler를 활용해서 EKS 워커 노드에 스팟 인스턴스 적용하기 (1) | 2021.12.09 |
| Logstash의 Kafka Input 성능 개선 이야기 (7) | 2021.10.28 |
| Connection Timeout과 Read Timeout 살펴보기 (4) | 2021.10.07 |