ElasticSearch (이하 ES)의 가장 기본적인 동작은 바로 문서의 색인과 조회입니다. 검색하고자 하는 문서를 색인하고 색인된 문서에 대한 검색 결과를 사용자에게 돌려주는 것이 ES의 가장 기본적인 동작이며 가장 핵심적인 동작이죠. 그리고 이런 동작들의 중심에는 샤드들이 있습니다. 또한 색인 성능, 검색 성능의 튜닝도 샤드를 잘 배치하는 것에서부터 시작합니다. 오늘 글에서는 ES의 두 샤드, 프라이머리 샤드와 레플리카 샤드에 대해 살펴보고 프라이머리 샤드 개수를 잘 설정하는 게 왜 중요한지 성능에 어떤 영향을 주는지에 대해서 살펴보겠습니다.
샤드의 종류
먼저 ES의 샤드에 대해서 살펴보겠습니다. ES에는 크게 프라이머리 샤드와 레플리카 샤드, 두 종류의 샤드가 있습니다. 그 이름에서 역할을 유추해 볼 수 있듯이 프라이머리 샤드는 데이터가 저장되는 원본 샤드를 의미하고, 레플리카 샤드는 프라이머리 샤드를 복제한 복제 샤드를 의미합니다. 레플리카 샤드는 복제 샤드 이기 때문에 프라이머리 샤드에 장애가 발생해서 해당 프라이머리 샤드가 정상적인 동작을 할 수 없을 때 프라이머리 샤드로 역할이 변경됩니다. 그리고 이런 과정을 통해 ES는 클러스터의 안정성을 확보하게 됩니다. 그럼 이 두 샤드는 구체적으로 어떤 역할을 맡고 있을까요?
프라이머리 샤드와 레플리카 샤드는 이름도 다르고 역할도 다르기 때문에 ES에서 담당하는 역할도 다릅니다. 무엇보다 두 샤드의 가장 큰 차이점은 바로 색인 작업에 참여하느냐 하지 않느냐입니다.
프라이머리 샤드는 데이터 원본을 저장해야 하기 때문에 데이터를 색인합니다. 따라서 색인과 검색에 모두 참여하게 되고, 레플리카 샤드는 프라이머리 샤드의 복제본이기 때문에, 즉 프라이머리 샤드가 데이터 색인을 완료한 후 그 완료된 상태를 복제하기 때문에 색인에는 참여하지 않습니다. 하지만 데이터를 가지고 있다는 것은 프라이머리 샤드와 같이 때문에 검색에는 참여합니다. 바로 이게 두 샤드가 가지는 가장 큰 차이점입니다.
프라이머리 샤드는 색인과 검색에 모두 영향을 미치고, 레플리카 샤드는 검색에만 영향을 미칩니다.
따라서 프라이머리 샤드의 개수는 색인과 검색 성능에 영향을 주고, 레플리카 샤드의 개수는 검색 성능에 영향을 줍니다. 예제를 통해 좀 더 살펴보겠습니다.
샤드 개수의 중요성
nginx에서 발생하는 액세스 로그를 수집한다고 가정해 보겠습니다. 인덱스의 이름은 아마도 nginx-access-log-YYYY.MM.DD의 형태가 되겠죠. 만약 아무런 설정을 하지 않았다면 기본값에 의해 해당 인덱스의 프라이머리 샤드는 1개, 레플리카 샤드도 1개 생성될 겁니다. 그리고 클러스터에는 데이터 노드가 2대 있다고 가정해 보겠습니다. 그럼 아래 그림과 같이 샤드가 배치되겠죠.
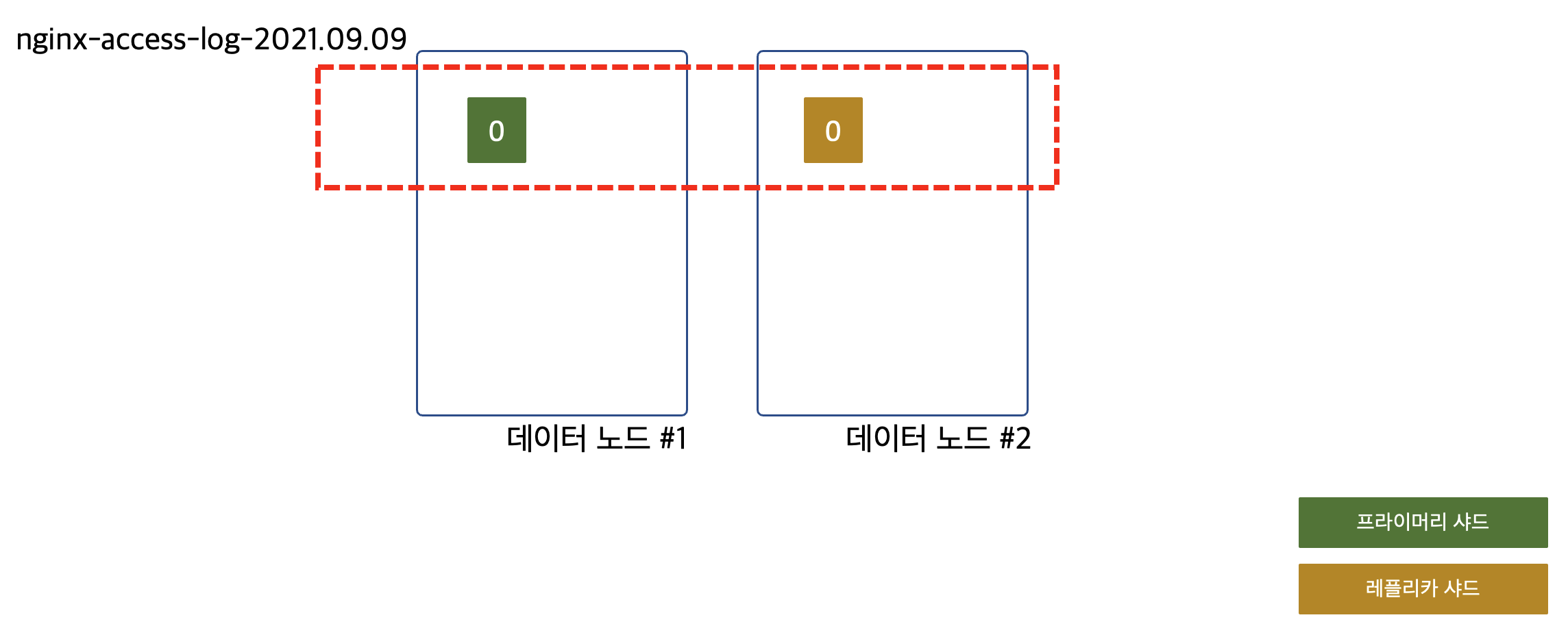
nginx-access-log-2021.09.09 인덱스의 0번 프라이머리 샤드는 데이터 노드 #1에 0번 레플리카 샤드는 데이터 노드 #2에 배치가 될 겁니다. 이 상황에서 nginx의 액세스 로그들에 대한 색인은 0번 샤드, 즉 데이터 노드 #1에서만 발생합니다. 데이터 노드는 2대지만 색인은 1대에서만 이뤄지고 있는 것입니다. 데이터 노드 한 대는 색인을 하지 않고 검색에만 참여하게 되죠. 왜냐하면 데이터 조회 시 로그는 프라이머리 샤드에서 가져오든 레플리카 샤드에서 가져오든 아무 곳에서나 가져올 수 있기 때문입니다. 이 상황에서 클러스터에 데이터 노드를 한 대 더 추가하면 어떻게 될까요?
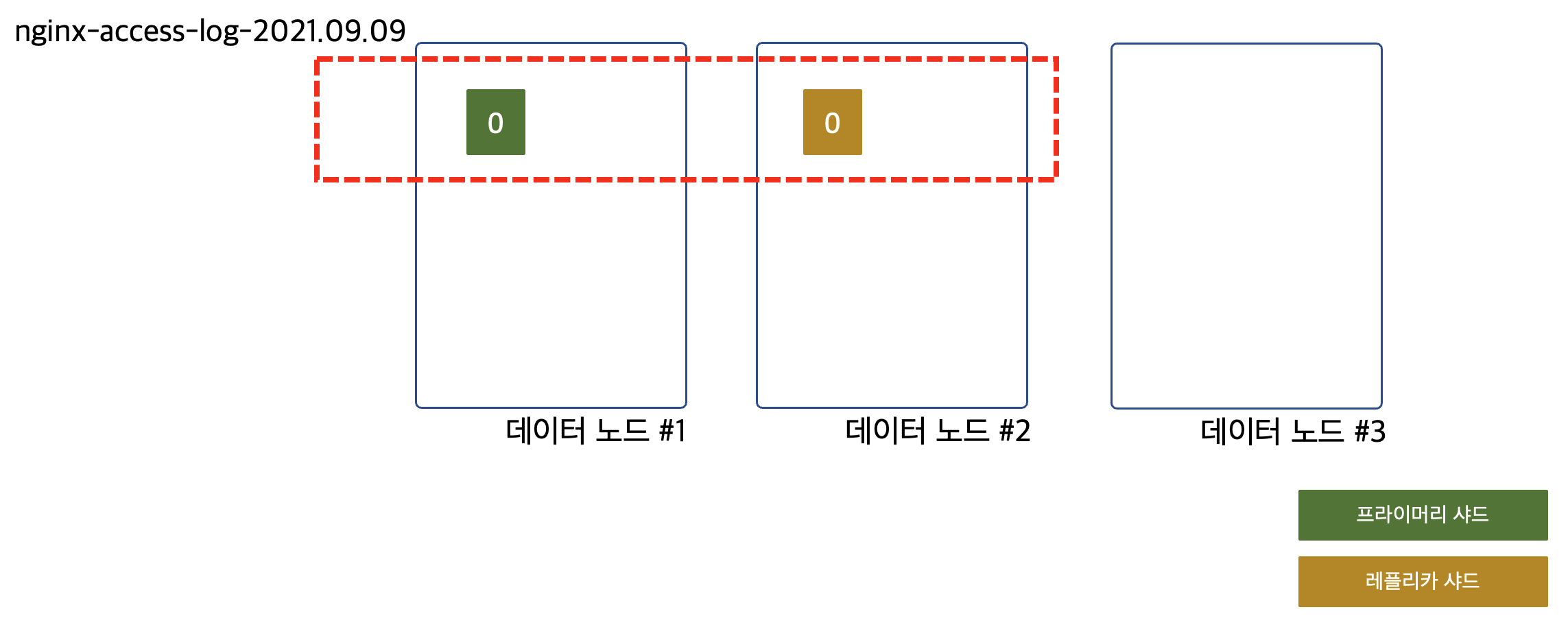
보이시나요? 용량이 부족하다고 느껴서던 색인 성능이 부족하다고 느껴서든 데이터 노드를 하나 더 추가했지만 아무 일도 일어나지 않습니다.
데이터 노드 #3에 나눠줄 샤드가 없어서입니다.
데이터 노드 #3이 호기롭게 다른 데이터 노드들을 도와주기 위해 클러스터에 합류했지만 아무런 도움이 되지 않습니다. 이 상황에서 index.number_of_replicas를 하나 더 늘려서 레플리카 샤드를 추가하면 어떻게 될까요?
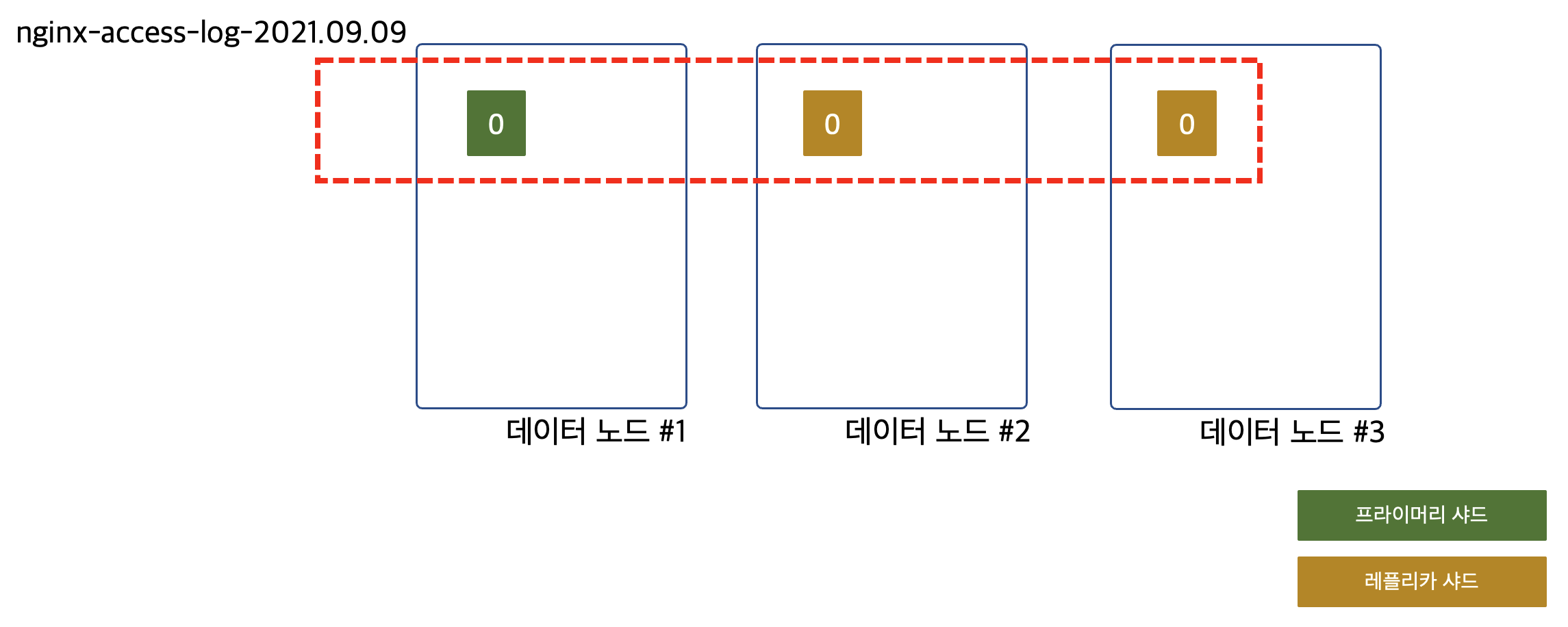
하나 더 생성된 레플리카 샤드는 이제 아무것도 없던 데이터 노드 #3에 배치가 됩니다. 자, 이제 데이터 노드 #3은 일을 할 수 있게 되었습니다. 하지만 앞에서도 이야기한 것처럼 레플리카 샤드는 검색 시에만 필요하기 때문에 검색 성능은 늘어났을지 몰라도 색인 성능은 여전히 그대로입니다. 검색 성능은 기존에 2대가 하던 검색 작업을 3대가 하게 되었으니 50% 정도 향상이 되었습니다. 하지만 색인 성능은 여전히 3대 중 한 대만하고 있기 때문에 좀 더 많은 문서를 색인할 수 있다거나, 더 빠르게 색인할 수 있다거나 하지 않습니다. 이게 바로 샤드 개수를 제대로 설정하지 않았을 때의 문제점입니다. 클러스터에 데이터 노드를 추가했지만 아무런 효과를 볼 수가 없는 경우가 생깁니다.
여기서 만약 프라이머리 샤드의 개수를 2개로 설정한다면 어떻게 될까요?
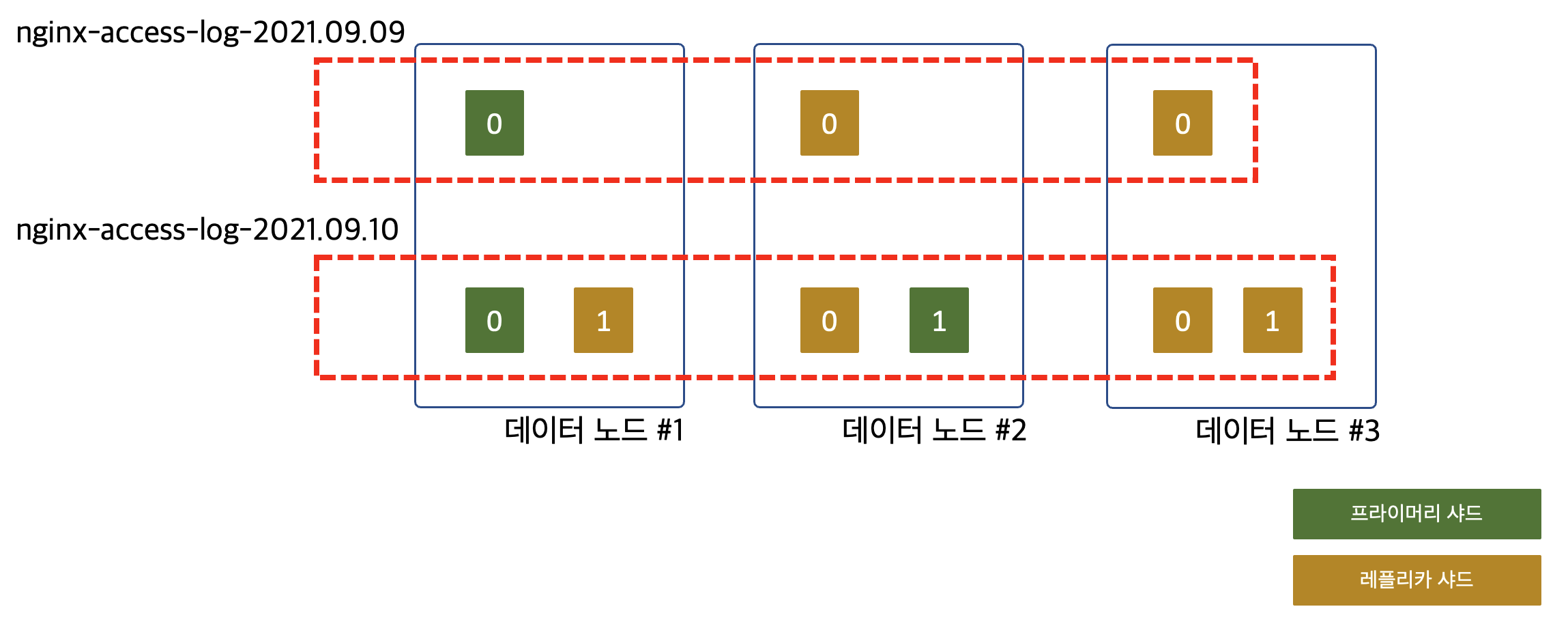
이제 9월 10일부터 수집하는 nginx의 액세스 로그는 9월 9일보다 두 배 빠르게 수집할 수 있게 되었습니다. 데이터 노드 #1과 #2가 같이 색인을 하기 때문입니다. 이렇게 프라이머리 샤드의 개수를 늘림으로써 더 많은 노드들이 색인에 참여할 수 있게 되었습니다. 하지만 지금도 3대의 데이터 노드 중 2대만 색인을 하기 때문에 아쉬운 상태 이긴 합니다.
그럼 가장 어려운 문제, 적당한 샤드의 개수는 어떻게 설정해야 할까요?
적당한 샤드의 개수, 그리고 조심해야 할 것
앞서 살펴봤던 것처럼 프라이머리 샤드의 개수가 적절해야 클러스터에 노드를 추가했을 때 성능 향상을 기대해 볼 수 있습니다. 기본 설정인 프라이머리 샤드 1개, 레플리카 샤드 1개로 사용하면 아무리 클러스터에 노드를 추가해도 성능이 늘어나지 않습니다.
따라서 최소한 클러스터에 구성하고자 하는 데이터 노드의 개수 정도로는 프라이머리 샤드의 개수를 맞춰야 클러스터 내의 모든 데이터 노드들을 색인 작업에 참여하게 할 수 있습니다.
그리고 향후 데이터 노드가 늘어났을 때를 대비해서 데이터 노드의 개수보다 조금 더 많게 오버 프로비저닝 하는 것도 괜찮습니다. 하지만 오버 프로비저닝을 했을 경우 조심해야 할 것들이 있습니다. 바로 노드 당 배치될 수 있는 샤드의 개수입니다.
ES에는 cluster.max_shards_per_node 설정이 있습니다. 이름 그대로 노드 당 배치할 수 있는 샤드의 최대 개수입니다. 그리고 이 값의 기본 설정값은 1,000입니다. 이 설정에 의해 노드 당 1,000개 이상의 샤드는 배치가 될 수 없습니다. 이 값은 클러스터 세팅에 의해 변경될 수 있지만 가급적 변경하지 않는 것을 권고합니다. 따라서 오버 프로비저닝 혹은 프라이머리 샤드의 개수를 1이 아닌 다른 값으로 설정할 때 이 값을 넘기게 되진 않는지 모니터링이 필요합니다.
마치며
오늘은 샤드 개수의 중요성에 대해서 살펴봤습니다. ES 클러스터를 설계할 때는 무엇보다 프라이머리 샤드와 레플리카 샤드의 기능적 차이를 잘 이해해야 합니다. 성능 문제를 겪게 되는 가장 큰 원인이 바로 잘못 설정된 샤드의 개수에 있는 경우가 많습니다. 클러스터에 데이터 노드를 증설했는데도 성능이 늘어나지 않거나 노드 간 데이터 불균형이 심하다면 가장 먼저 의심해 봐야 할 것이 샤드 배치입니다. 프라이머리 샤드가 모든 데이터 노드들에 걸쳐서 균등하게 잘 배치되어 있는지, 레플리카 샤드들도 충분히 배치되어 있는지를 가장 먼저 살펴보고 그 이후에 하드웨어를 더 좋은 사양으로 업그레이드하거나 하는 작업을 통해 성능을 향상해야 합니다. 이번 글이 ES의 성능 문제로 어려움을 겪고 계신 분들에게 도움이 되었으면 좋겠습니다.